

Big Data & Cloud Architect

Cloud Data Solutions Engineer/Architect

Analytics Engineer | GCP | AWS | Python Dev | Azure | Databricks | Spark

Cloud Engineer | 3x AWS Certified | 2x HashiCorp Certified | GitHub: ajaen4

This article is the second in a two-part series aimed at addressing the integration of Databricks in AWS environments by analyzing the alternatives offered by the product concerning architectural design. The first part discussed topics more related to architecture and networking, while in this second installment, we will cover subjects related to security and general administration.
The contents of each article are as follows:
First installment:
This installment:
The first article can be visited at the following link.
Visit Data security and encryption this link
Databricks introduces data security configurations to safeguard information in transit or at rest. The documentation provides a comprehensive overview of the available encryption features. These features encompass:
Customer-managed keys for encryption: Enabling the protection and access control of data in the Databricks control plane, including source files of notebooks, notebook results, secrets, SQL queries, and personal access tokens.
Encryption of traffic between cluster nodes: Ensuring the security of communication between nodes within the cluster.
Encryption of queries and results: Securing the privacy of queries and the stored results.
Encryption of S3 buckets at rest: Providing security for data stored in S3 buckets.
It’s essential to highlight that within the support for customer-managed keys:
Another capability offered by Databricks is the use of AWS KMS keys to encrypt SQL queries and their history stored in the control plane.
Lastly, it also facilitates the encryption of traffic between cluster nodes and the administration of security configurations for the workspace by administrators.
In this article, we will delve into two of the options: customer-managed keys and the encryption of traffic between cluster worker nodes.
Visit Customer-managed keys this link
Databricks account administrators can configure managed keys for encryption. Two use cases are highlighted for adding a customer-managed key: data from managed services in the Databricks control plane (such as notebooks, secrets, and SQL queries) and workspace storage (root S3 buckets and EBS volumes).
It’s important to note that managed keys for EBS volumes do not apply to serverless compute resources, as these disks are ephemeral and tied to the lifecycle of the serverless workload. In the Databricks documentation, there are comparisons of use cases for customer-managed keys, and it is mentioned that this feature is available in the Enterprise subscription.
Regarding the concept of encryption key configurations, these are account-level objects that reference user cloud keys. Account administrators can create these configurations in the account console and associate them with one or more workspaces. The configuration process involves creating or selecting a symmetric key in AWS KMS and subsequently editing the key policy to allow Databricks to perform encryption and decryption operations. Detailed instructions, along with examples of necessary JSON policies for both use configurations (managed services and workspace storage), can be found in the documentation.
Lastly, there is the option to add an access policy to a cross-account IAM role in AWS, in case the KMS key is in a different account.
For this part, it is crucial to emphasize the importance of the init script.
In Databricks, it is crucial to highlight the significance of the init script, which, among other functions, is used to configure encryption between worker nodes in a Spark cluster. This init script enables the retrieval of a shared encryption secret from the key scope stored in DBFS. If the secret is rotated by updating the key store file in DBFS, all running clusters must be restarted to avoid authentication issues between Spark workers and the driver. It’s noteworthy that, since the shared secret is stored in DBFS, any user with access to DBFS can retrieve the secret through a notebook.
While specific AWS instances automatically encrypt data between worker nodes without additional configuration, using the init script provides an added level of security for data in transit or complete control over the type of encryption to be applied.
The script is responsible for obtaining the secret from the key store and its password, as well as configuring the necessary Spark parameters for encryption. Launched as Bash, it performs these tasks and, if necessary, waits until the key store file is available in DBFS and derives the shared encryption secret from the hash of the key store file. Once the initialization of the driver and worker nodes is complete, all traffic between these nodes will be encrypted using the key store file.
These features are part of the Enterprise plan.
Databricks supports two main types of persistent storage: DBFS (Databricks File System) and S3 (Amazon Simple Storage Service).
DBFS
DBFS is an integrated distributed file system directly connected to Databricks, storing data in the cluster and workspace’s local storage. It provides a file interface similar to standard HDFS, facilitating collaboration by offering a centralized place to store and access data.
S3
On the other hand, Databricks can also connect directly to data stored in Amazon S3. S3 data is independent of clusters and workspaces and can be accessed by multiple clusters and users. S3 stands out for its scalability, durability, and the ability to separate storage and computation, making data access easy even from multiple environments.
Regarding metastores, Databricks on AWS supports various types, including:
Hive Metastore
Databricks can integrate with the Hive metastore, allowing users to use tables and schemas defined in Hive.
Glue Metastore in Data Plane
Databricks also has the option to host the metastore in the compute plane itself with Glue.
These metastores enable users to manage and query table metadata, facilitating schema management and integration with other data services. The choice of metastore will depend on the specific workflow requirements and metadata management preferences in the Databricks environment on AWS.
Unity Catalog
Undoubtedly, a new feature of Databricks that unifies these previous metastores and enhances the various options and tools each of them offers is the Unity Catalog.
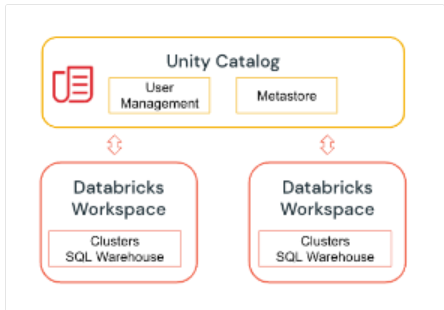
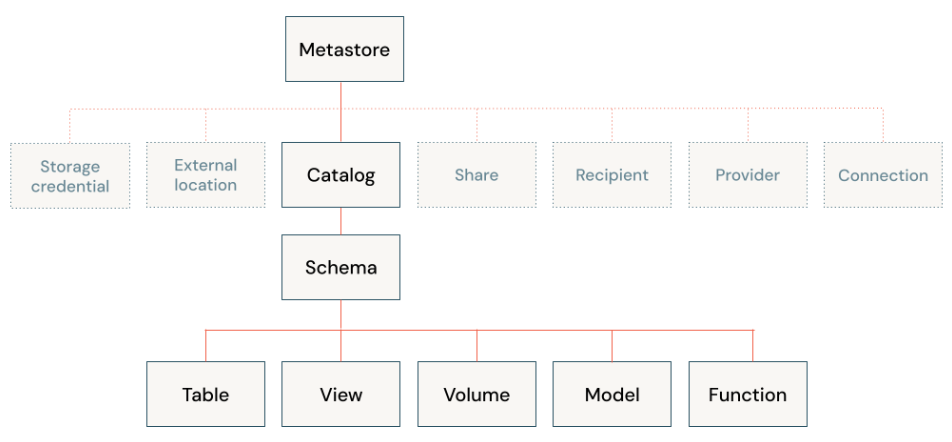
Unity Catalog provides centralized capabilities for access control, auditing, lineage, and data discovery.
Key Features of Unity Catalog:
Databricks recommends configuring all access to cloud object storage through Unity Catalog to manage relationships between data in Databricks and cloud storage.
Here is a detailed explanation of Databricks’ function on AWS that enables the delivery and access to billable usage logs. Account administrators can configure the daily delivery of CSV logs to an AWS S3 bucket. Each CSV file provides historical data on the usage of clusters in Databricks, categorizing them by criteria such as cluster ID, billing SKU, cluster creator, and tags. The delivery includes logs for both running workspaces and those canceled, ensuring the proper representation of the last day of such a workspace (it must have been operational for at least 24 hours).
The setup involves creating an S3 bucket and an IAM role in AWS, along with calling the Databricks API to set up storage configuration objects and credentials. The cross-account support option allows delivery to different AWS accounts through an S3 bucket policy. CSV files are located at <bucket-name>/<prefix>/billable-usage/csv/, and it is advisable to review S3 security best practices.
The account API allows shared configurations for all workspaces or separate configurations for each space or group. The delivery of these CSVs enables account owners to directly download the logs. The S3 object ownership is auto-configured as “Bucket owner preferred” to support ownership of newly created objects.
There is a limit on the number of log delivery configurations, and one needs to be an account administrator, providing the account ID. Extra caution is required when configuring the S3 object property as “Object writer” instead of “Bucket owner preferred” due to potential access difficulties.
| Fields | Description |
|---|---|
| workspaceId | Workspace Id |
| timestamp | Established frequency (hourly, daily,…) |
| clusterId | Cluster Id |
| clusterName | Name assigned to the Cluster |
| clusterNodeType | Type of node assigned |
| clusterOwnerUserId | Cluster creator user id |
| clusterCustomTags | Customizable cluster information labels |
| sku | Package assigned by Databricks in relation to the cluster characteristics. |
| dbus | DBUs consumption per machine hour |
| machineHours | Cluster deployment machine hours |
| clusterOwnerUserName | Username of the cluster creator |
| tags | Customizable cluster information labels |
Big Data & Cloud Architect
Analytics Engineer | GCP | AWS | Python Dev | Azure | Databricks | Spark
Cloud Data Solutions Engineer/Architect
Cloud Engineer | 3x AWS Certified | 2x HashiCorp Certified | GitHub: ajaen4




